Translation Memory: Full Guide to Definition, Benefits, and Setup

In 2024, companies localizing content into multiple languages face a familiar challenge: how do you maintain consistency across thousands of documents while keeping translation costs under control? The answer lies in a technology that’s been quietly powering the translation industry for decades and that is translation memory.
This comprehensive guide covers everything you need to know about translation memory, from foundational concepts to advanced implementation strategies. Whether you’re a project manager evaluating translation memory software, a professional translator looking to boost productivity, or a localization lead scaling operations, you’ll find actionable insights to optimize your translation process.
What Is Translation Memory?
Translation memory (TM) is a specialized translation memory database that stores bilingual text segments, typically sentences, paragraphs, or UI strings paired with their corresponding translation in a target language. When you translate new content, the system searches this database and suggests previously translated segments that match or closely resemble your source text.
Think of it as institutional knowledge for your translations. Every time a human translator approves a translation, that work gets stored as a translation unit: a pairing of source language text with its target language equivalent, along with metadata like the date, author, client, and content domain. These translation units accumulate over time, building a valuable asset that accelerates future translations.
Translation memory TM emerged in commercial CAT tool environments in the late 1980s and has since become a core feature of virtually all computer-assisted translation and localization platforms. Unlike machine translation, which generates new translations algorithmically, TM reuses past translations that have already been validated by human translators. This distinction matters: stored translations carry the quality assurance of prior human input, ensuring your translated text maintains the brand voice and terminology your organization requires.
For example, if your user manual contains the phrase “Click Save to confirm your changes” and you’ve translated this into German before, the TM will suggest that exact German translation when the same phrase appears in your next project. No rework needed—the professional translator simply confirms the match.
Awtomated includes built-in translation memory, so users don’t need to manage external TM files or configure plugins. Your translation assets live within the platform, ready to support every localization project from day one.
How Does Translation Memory Work in Practice?

The translation memory work process follows a clear workflow: import your source file, segment the content, query the TM for matches, present suggestions to translators for review, and commit approved translations back to the database. Each step builds on the last to create a self-reinforcing system that grows smarter with every project.
Segmentation
When you upload a document, the translation memory tool breaks it into discrete segments. Most translation memory software works by splitting content at sentence boundaries—periods, question marks, exclamation points—though you can customize segmentation rules for specific content types. Software localization projects might segment at individual UI strings, while legal documents may preserve entire clauses as single units.
The Matching Process
Once segmentation is complete, the TM engine scans each segment against the translation memory database. It returns matches in two primary categories:
- Exact matches (100%): The new source segment is identical to a stored segment, including punctuation and formatting tags
- Fuzzy matches (75-99%): The segment is similar but contains minor differences—perhaps a changed number, date, or word
The system calculates a similarity score for each potential match, allowing translators to prioritize their review. Segments below a minimum threshold (often 70%) are flagged as “no match” or new content requiring full translation.
Translator Review and Confirmation
Human translators see the source text alongside TM suggestions in their CAT tool interface. They can accept a suggestion as-is, edit it to fit the new context, or ignore it and translate fresh. This human-in-the-loop approach ensures translation quality while maximizing efficiency from previously translated content.
The typical flow looks like this: upload the source file into your translation management system, let the platform analyze content against existing translation memory, review match percentages and suggestions segment-by-segment, confirm or modify translations with linguistic quality assurance in mind, and finally export the completed translated file while the TM updates automatically with new approved translations.
Types of Translation Memory Systems
Translation memory systems come in three main architectures: file-based, server-based, and cloud-native. Modern localization teams increasingly favor centralized cloud solutions, though the right choice depends on your team structure, security requirements, and collaboration model.
File-based TMs store translation data in local files, typically in formats like SDLTM or TMX. Freelance translators and small agencies often use this approach because files are portable and work offline. The downside? Version fragmentation becomes a real risk when multiple translators maintain separate translation memories for the same language pair. Merging becomes tedious, and you lose the benefit of real-time updates.
Server-based TMs run on dedicated infrastructure, either on-premises or hosted. Multiple translators connect to a central database, ensuring everyone works from the same source of truth. This model suits language service providers handling high volumes across many clients.
Cloud-native TMs integrate directly into browser-based translation management system platforms like Awtomated. They offer real-time sharing, granular permission controls, automatic backups, and zero infrastructure overhead. For organizations scaling multilingual content across different languages, cloud TM eliminates the friction of file exchanges and versioning headaches.
Many organizations also maintain separate translation memories for different products, brands, or content domains. A pharmaceutical company might keep distinct TMs for clinical trial documentation versus marketing materials—the terminology and regulatory requirements differ significantly. Others organize by language pair, maintaining per-language memories for cleaner reporting and quality control.
Different Match Types in Translation Memory
Translation memory returns matches with percentage scores that directly impact both translation speed and project pricing. Understanding these categories helps project managers budget accurately and helps translators prioritize their work.
Exact Matches (100%)
An exact match means the new source segment is identical to one stored in the TM—same text, same punctuation, same formatting tags. Language service providers typically bill these at significantly reduced rates (sometimes 10-30% of full translation cost) because the translator simply confirms accuracy rather than creating a new translation.
Context Matches (ICE Matches)
Context matches, also called in-context exact (ICE) matches, go one step further. Not only is the segment identical, but its surrounding context—the previous and following sentences or structural identifiers—also matches. This provides even higher confidence that the existing translation fits perfectly. Many tools, including Awtomated, flag context matches specially, and some organizations lock these segments to prevent accidental changes.
Fuzzy Matches (75-99%)
Fuzzy matches occur when minor differences exist between the source segment and stored translations. Perhaps a product version number changed, or a single word differs. A segment like “Update your account settings” might return a 90% fuzzy match to the stored “Update your account details”—close enough to save time, but requiring the translator’s judgment to adjust.
The higher the fuzzy match percentage, the less editing typically required. Most translation memory software categorizes fuzzy matches into bands (85-94%, 75-84%, etc.) with corresponding price adjustments.
No Match / New Segments
Segments falling below the minimum threshold—often set at 70% or 75%—count as no-match content. These require full human translation and subsequently become new translation entries in the TM database, enriching future projects.
Translation Memory vs. Termbase vs. Machine Translation
Translation memory, termbases (glossaries), and machine translation engines serve complementary roles in modern localization. Understanding how they work together—rather than viewing them as competing technologies—unlocks the most efficient workflows.
TM vs. Termbase
Translation memory stores complete segments: full sentences, paragraphs, or UI strings with their translations. A termbase, by contrast, stores individual terms with definitions, part of speech, usage notes, and approved equivalents. The same phrase might appear in a termbase as an isolated entry while also existing within multiple TM segments.
Termbases excel at maintaining consistency for product names, legal terms, technical jargon, and brand phrases. If your company always translates “cloud storage” as “almacenamiento en la nube” in Spanish, the termbase enforces this across all contexts. TM handles the full sentences containing that term, while the termbase ensures the term itself never gets translated differently.
TM vs. Machine Translation
Unlike machine translation, which uses neural networks or statistical models to generate new translations, TM reuses validated human work. Machine translation produces fast first drafts but may miss nuance, tone, or domain-specific terminology. TM provides proven, approved translations that maintain brand consistency and technical accuracy.
The most effective translation technology stacks combine both:
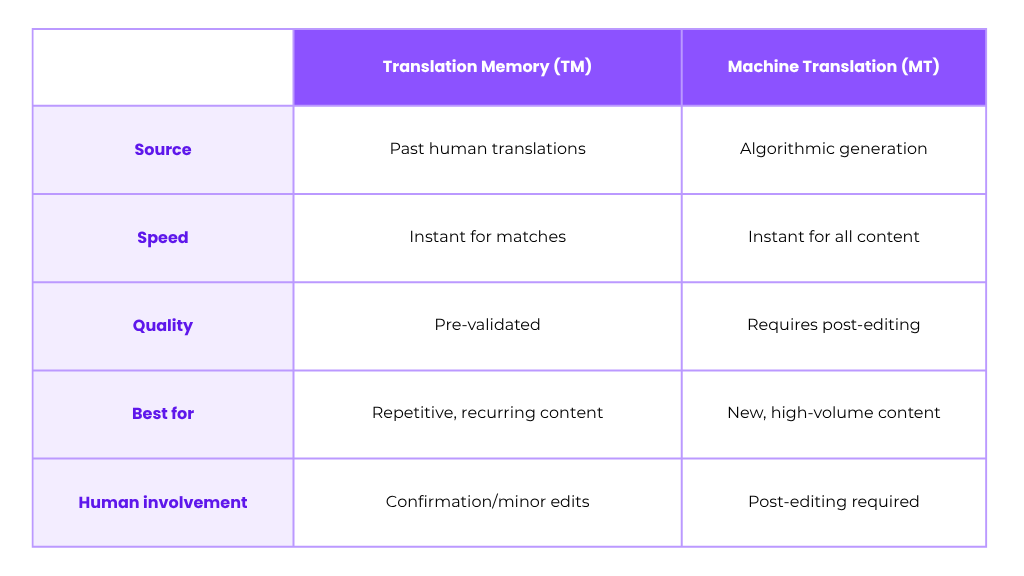
A typical workflow runs MT first to generate a raw draft, then overlays TM matches where available (prioritizing 100% and high fuzzy matches), applies termbase constraints, and routes everything to human translators for post-editing and quality assurance. Awtomated combines TM and MT with human-in-the-loop review, giving you the speed of automation with the quality of human validation.
History and Evolution of Translation Memory
Translation memory’s roots trace back to the late 1970s when researchers began exploring how computers might assist—rather than replace—human translators. Martin Kay’s influential 1980 paper “The Proper Place of Men and Machines in Language Translation” articulated a vision of computer-aided translation that preserved human expertise while automating repetitive tasks.
Commercial CAT tools with TM capabilities emerged in the late 1980s and proliferated through the 1990s. Products like Trados and Déjà Vu standardized segment-based reuse, transforming how language service providers and enterprise localization teams operated. For the first time, past translations became reusable assets rather than one-time deliverables.
The 2000s brought industry-wide standards for interoperability. The Localization Industry Standards Association (LISA) developed TMX (Translation Memory eXchange) around 2002, enabling TM data to move between different tools. TBX standardized terminology exchange, XLIFF standardized translatable content packaging, and suddenly organizations weren’t locked into single-vendor ecosystems.
The 2010s and 2020s saw translation technology migrate to the cloud. Browser-based CAT tools democratized access, server infrastructure moved to managed platforms, and neural machine translation integration became standard. What once required desktop software and manual file exchanges now happens in real-time across distributed teams.
Awtomated represents this new generation: cloud-native TM integrated with automation workflows, APIs connecting to CMS and code repositories, and AI-powered features that enhance rather than replace the foundational TM technology that’s proven its value over four decades.
Key Benefits of Translation Memory
The benefits of translation memory compound over time. Organizations with mature TM programs report 20-50% faster turnaround and 15-40% cost reduction on repetitive content. Here’s how those gains materialize.
Consistency Across All Content
Translation memory helps ensure the same phrase gets the same translation everywhere it appears—across product manuals, UI strings, marketing materials, and support documentation. This maintaining consistency protects brand voice and prevents the confusion that arises when the same text appears translated differently in different places.
In practice, mature TMs achieve 99% consistency rates compared to roughly 85% in ad-hoc translation approaches. For brands maintaining voice across 50+ languages, this difference matters enormously.
Significant Cost Savings
Language service providers apply discounted rates for TM matches. A 50,000-word technical documentation project with 40% leverage from past translations might reduce the translation budget by 30-35%. The math is straightforward: you’re not paying to translate content that already exists in validated form.
In high-repetition environments like software localization or annual product manuals, TM leverage rates often exceed 60%—meaning more than half the content requires no new human effort beyond confirmation.
Reduced Risk and Higher Quality
TM prevents “reinventing” translations for recurring content. Legal disclaimers, safety warnings, regulatory statements, and technical specifications maintain their approved phrasing across documents and versions. In industries like pharmaceuticals, finance, and manufacturing, this consistency isn’t just convenient—it’s often required for compliance.
Faster Time-to-Market
When launching product updates or expanding to new locales, previously translated content gets prefilled automatically. Teams can focus human attention on genuinely new material rather than re-translating boilerplate. This enables near-simultaneous global releases instead of staggered rollouts waiting for translation completion.
Translator Productivity and Satisfaction
From the freelance translators and in-house linguist perspective, TM reduces tedious repetitive typing. Rather than translating the same UI string for the hundredth time, they focus on nuanced new content where their expertise adds real value. This boost productivity while improving job satisfaction—a win for retention and quality alike.
When and Where to Use Translation Memory
Translation memory delivers the greatest ROI for content featuring repeated or semi-repeated text across versions, markets, or file formats. Not all content benefits equally—knowing where to focus your TM strategy maximizes returns.
High-Value Use Cases
- Software and app UI strings: Buttons, menus, error messages, and notifications repeat constantly across releases
- Technical documentation: User manuals, API documentation, installation guides, and product manuals evolve incrementally
- E-commerce product descriptions: Attribute templates, size guides, and shipping policies share common structures
- Legal contracts and terms: Clauses, disclaimers, and boilerplate persist across agreements
- Knowledge base articles: Troubleshooting steps and procedural instructions follow patterns
- Marketing email templates: Headers, footers, CTAs, and promotional structures recur seasonally
Consider a SaaS company releasing monthly product updates. Each release note contains 70% recurring structure (navigation instructions, standard disclaimers, UI references) and 30% new feature descriptions. Translation memory handles the recurring portion instantly, letting translators focus entirely on the new material.
Similarly, a hardware manufacturer updating a 200-page user manual annually might find 60-70% of content unchanged between versions. Without TM, that’s redundant translation cost every year. With TM, those pages auto-populate from saved translations.
Where TM Provides Limited Value
For literary translation, creative advertising copy, and highly stylized brand campaigns, TM helps primarily with recurring brand terms and legal boilerplate rather than core creative content. A novel’s prose shouldn’t feel templated, and a marketing tagline needs fresh creative adaptation, not segment-level reuse.
That said, even creative projects benefit from TM for peripheral content: copyright notices, author bios, legal statements, and recurring structural elements.
How to Create a Translation Memory
Organizations can build TMs from scratch during ongoing projects or jumpstart their database by aligning previously translated materials. Either approach creates a foundation that grows more valuable with each project.
Starting from Zero
The simplest path: enable TM in a platform like Awtomated, translate new content, and let every confirmed segment automatically populate the translation memory database. Your first project may show no TM leverage, but subsequent projects immediately benefit. Within 3-5 translation cycles, most organizations see substantial leverage rates.
Aligning Existing Translations
If your company has existing translations—old versions of user manuals, previously localized websites, archived marketing materials—you can extract value from that past work through TM alignment.
The process works like this:
- Gather source and target files: Locate both the source language and original language versions of previously translated documents
- Import into alignment tool: Use your CAT tool or Awtomated’s alignment features to pair the documents
- Segment and match: The tool breaks both versions into segments and attempts to pair corresponding source-target units
- Review alignment: Human review catches misalignments, skipped segments, or quality issues in the legacy translations
- Import to production TM: Validated pairs become translation units in your active translation memory
- Apply metadata: Tag entries with client, product, date, and domain information for better filtering
Awtomated can ingest legacy TMs in TMX format, so if you’re migrating from another platform, you don’t lose your existing translation assets. Teams keep institutional knowledge instead of starting over.
Common source file formats supported include DOCX, HTML, XML, JSON, PO files, XLIFF, and InDesign (IDML). Each format has segmentation nuances—your TM software handles these automatically based on configured rules.
How to Manage and Maintain Translation Memory
An unmanaged translation memory quickly accumulates noise: duplicate entries, outdated translations, deprecated terminology, and quality inconsistencies. Proactive maintenance keeps your TM a reliable asset rather than a liability.
Establish Governance
Designate TM owners—typically language leads for each locale—responsible for reviewing entries and enforcing style and terminology rules. Clear ownership prevents the “tragedy of the commons” where everyone adds content but no one curates it.
Routine Maintenance Tasks
- Deduplication: Remove identical entries that waste storage and clutter search results
- Merge near-identical segments: Consolidate variations that should have consistent translations
- Remove outdated translations: Product names change, features get deprecated, regulatory language evolves—your TM should reflect current reality
- Correct mistranslations: QA catches errors that slipped into the TM; fix them at the source
Schedule Periodic Audits
Manage translation memory health through scheduled reviews—every 6 or 12 months, or after major product rebrands. During audits, examine leverage reports, identify stale content, and reorganize memories that have grown unwieldy.
Use Metadata Effectively
Rich metadata (client name, product, domain, date, status) enables smart filtering. When translating a new mobile app, you might prioritize matches from your mobile TM over matches from desktop documentation. When updating 2024 content, you might deprioritize translations from 2019.
In Awtomated, admins configure permissions so only trusted linguists or reviewers can modify or delete TM entries in production memories. This prevents accidental corruption while enabling appropriate access for legitimate updates.
Best Practices for Using Translation Memory Effectively
TM quality depends on source text quality, workflow design, and disciplined usage across the organization. These best practices maximize your translation memory investment.
Author for Reuse
Write clear, concise, repeatable source sentences. Avoid unnecessary variation in UI labels—if three screens say “Save,” “Save Changes,” and “Save Your Work” but mean the same thing, consolidate them. Controlled authoring in the source language directly improves TM leverage downstream.
Centralize Translation Work
Ensure all linguists access the same master TM rather than maintaining private, disconnected memories. Separate translation memories for the same content create divergence and duplicate effort. A single source of truth compounds value faster.
Combine TM with Style Guides and Termbases
Translation memory suggestions should align with your terminology database and style standards. Configure your CAT tool to flag termbase violations in TM suggestions—a stored translation might use an outdated product name or deprecated terminology.
Prioritize Multiple TMs Appropriately
When multiple TMs exist (client-specific, domain-specific, legacy), configure priority and penalty settings. Apply client master TM first at full confidence, then generic TMs with lower match penalties. This ensures the most relevant suggestions surface first.
Lock High-Confidence Segments
For context matches and legally approved boilerplate, consider locking segments to prevent accidental changes. Regulatory content in pharmaceutical or financial documentation shouldn’t be casually edited—lock it, and require explicit override authorization.
Risks, Limitations, and How to Avoid Error Propagation

Poor-quality or outdated TM content propagates errors rapidly across large content sets. Awareness of these risks enables proactive mitigation.
Error Propagation
Once a mistranslation enters the TM, it can auto-populate hundreds of future segments. A single typo in a product name, or a subtle meaning error in a legal phrase, multiplies across every document using that TM. Quality assurance before committing translations to TM is essential—review thresholds should be high for additions that will affect future translations.
Over-Reliance on Suggestions
Translators may mechanically accept TM suggestions without verifying contextual fit. The same phrase might require different translations depending on surrounding content. Training linguists to evaluate suggestions critically—not just accept high percentages automatically—maintains quality.
Fragmentation from Parallel TMs
When multiple teams maintain separate TMs for the same language pair and content domain, inconsistency creeps in. The same source text ends up translated differently depending on which TM was consulted. Consolidation strategies and clear naming conventions prevent this drift.
Technical Safeguards
Implement automated QA checks: placeholder validation, number verification, terminology enforcement. Conduct LQA sampling where senior linguists review TM additions. Maintain change logs enabling rollback of problematic entries.
Consider a practical scenario: your company rebranded in 2023, changing the product name from “CloudSync” to “SyncFlow.” Every TM entry containing the old name needs updating, or new translations will carry outdated branding. Metadata search and bulk-edit capabilities make such updates manageable.
Interoperability and Translation Memory Standards
Companies change tools, work with multiple vendors, and must avoid lock-in. Interoperability standards protect your translation assets regardless of platform choices.
TMX (Translation Memory eXchange) is the de facto XML-based standard for sharing translation memories between tools. When migrating to a new platform like Awtomated, you export TMX from your old system and import it directly—no data loss, no manual recreation.
TBX (TermBase eXchange) serves the same purpose for terminology databases, while SRX (Segmentation Rules eXchange) ensures consistent segmentation across tools. XLIFF (XML Localization Interchange File Format) standardizes how translatable content gets packaged for localization workflows.
You’ll also encounter format-specific files in localization projects: Gettext PO files for open-source software, JSON resource files for web applications, and various proprietary formats. Modern platforms can import and export these while preserving TM links and metadata.
Always request TMX exports from language service providers to retain ownership of your translation assets.
Your translations represent significant investment—don’t let them stay locked in a vendor’s proprietary system. Standards-based export means you can move your TM to Awtomated or any other compliant platform whenever business needs change.
How Translation Memory Integrates into Modern Localization Workflows
Contemporary localization operates on continuous workflows: frequent code pushes, content updates, and design iterations flow through translation pipelines in near-real-time. TM sits at the center of these operations.
Repository and CMS Integration
Strings sync automatically from GitHub, GitLab, Bitbucket, or content management systems like WordPress and Contentful. When developers push new UI strings or content authors update documentation, the localization platform detects changes and applies TM suggestions on import. No manual file handling, no export/import cycles.
Real-Time Collaboration
Translators, reviewers, and product teams work in parallel, with TM suggestions visible to all contributors simultaneously. A translator in Berlin confirms a segment; a reviewer in Tokyo sees it instantly. This collaboration model accelerates turnaround and catches issues early.
Automation and Pre-Translation
Connectors pre-translate content using TM combined with machine translation. Segments with 100% matches get auto-filled; high fuzzy matches get MT suggestions; new content routes to human translators. The entire pipeline runs automatically, with humans focusing where they add most value.
Awtomated exemplifies this integrated approach: built-in TM connects to automation rules, APIs, and webhooks, enabling end-to-end pipelines without manual TM file handling. Translate content as fast as your product evolves.
Choosing Translation Memory Software (and Where Awtomated Fits)

The right TM implementation depends on team size, content volume, technical stack, and collaboration model. Evaluating options systematically ensures you choose a platform that scales with your needs.
Key Evaluation Criteria
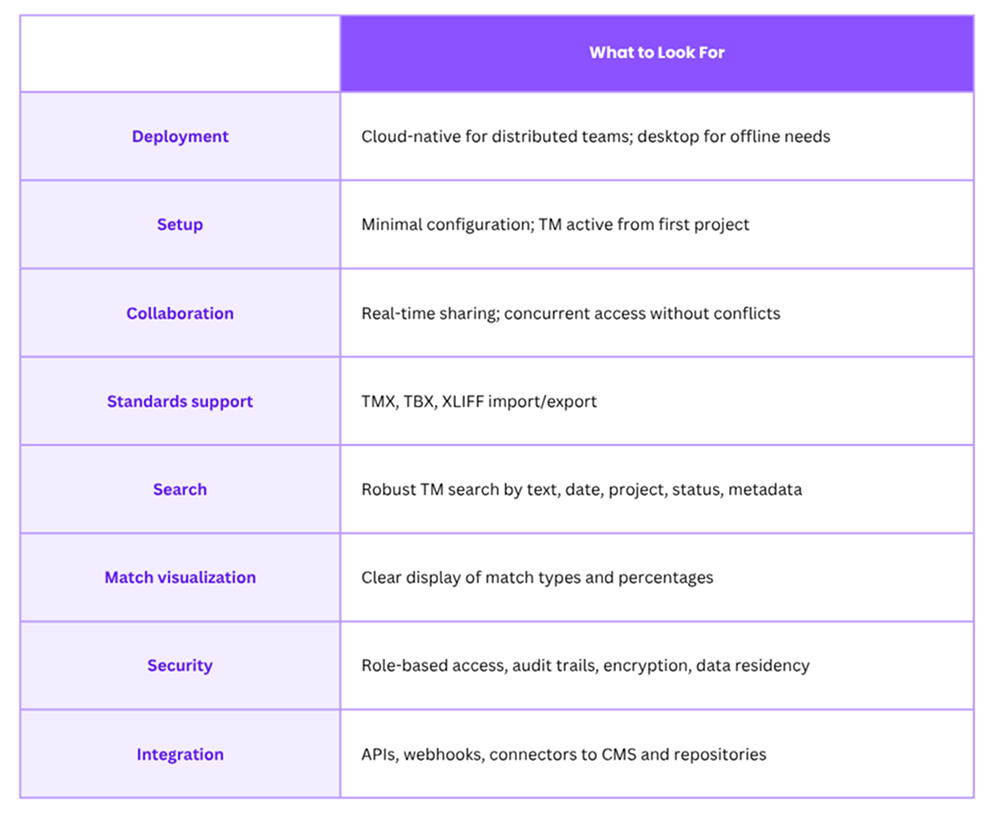
Usability Matters
Both linguists and non-linguists (project managers, content authors) interact with TM systems. Intuitive interfaces, powerful concordance search, and clear match-type visualization accelerate adoption and reduce training overhead.
Where Awtomated Fits
Awtomated provides built-in TM integrated with machine translation, automation workflows, and connectors to common content platforms. You don’t need to configure external TM files, set up integrations manually, or manage infrastructure. The platform tracks TM leverage and savings through analytics, demonstrating ROI to stakeholders.
For organizations evaluating TM software, consider piloting with a real project—perhaps a product update in 2-3 languages. Measure improvements in speed, cost, and consistency compared to your pre-TM workflow. The results typically speak for themselves.
Future of Translation Memory
Translation memory continues evolving alongside neural MT and AI-assisted authoring tools. The fundamental value proposition—reusing validated human translations—remains constant, but capabilities are expanding rapidly.
AI-Enhanced TM Features
Modern TM systems incorporate predictive suggestions, automatic clustering of similar segments, and adaptive fuzzy matching that learns project-specific preferences. These features reduce human intervention by 25-35% in early implementations, with continued improvement expected.
Translation Memory as Corporate Language Asset
Organizations increasingly treat TM as strategic data, feeding analytics on terminology usage, tone consistency, and customer-facing messaging. This data informs not just translation but source authoring, product naming, and brand strategy.
Integration with Large Language Models
The trend toward integrating TM with LLMs promises the best of both approaches: generative AI produces fluent output while TM constrains and grounds that output to ensure brand consistency and factual accuracy. High quality translations emerge faster, with fewer hallucinations or off-brand phrasing than pure LLM approaches.
Awtomated is built to leverage both classic TM and emerging AI capabilities. As the translation industry evolves, the platform evolves with it—ensuring your localization operations stay efficient and competitive regardless of how the technology landscape shifts.
Key Takeaways
- Translation memory stores bilingual segment pairs, enabling reuse of past translations validated by human translators
- TM delivers 20-50% cost reduction and 30-40% productivity gains for repetitive content
- Match types (exact, context, fuzzy, no-match) directly impact speed and pricing
- TM complements both termbases (for terminology) and machine translation (for first-draft generation)
- Regular maintenance prevents error propagation and keeps TM assets reliable
- Standards like TMX ensure portability across platforms and vendors
- Awtomated’s built-in TM integrates with automation workflows for end-to-end localization
Conclusion
Translation memory represents four decades of proven translation technology, refined through countless localization projects across every industry. It’s not glamorous—no AI hype, no blockchain buzzwords—but it works. Organizations that invest in building, maintaining, and strategically deploying TM gain cumulative advantages that compound over years and across languages.
Whether you’re launching a localization program from scratch or optimizing an existing operation, translation memory belongs at the foundation. Start by auditing any existing translations that could seed your TM, establish governance practices from day one, and choose a platform like Awtomated that makes TM seamlessly accessible to your entire team.
The work you translate today should make tomorrow’s translation faster, cheaper, and more consistent. That’s the promise of translation memory—and it’s a promise the technology delivers.
Table of Contents
- What Is Translation Memory?
- How Does Translation Memory Work in Practice?
- Different Match Types in Translation Memory
- Translation Memory vs. Termbase vs. Machine Translation
- History and Evolution of Translation Memory
- Key Benefits of Translation Memory
- When and Where to Use Translation Memory
- How to Create a Translation Memory
- How to Manage and Maintain Translation Memory
- Best Practices for Using Translation Memory Effectively
- Interoperability and Translation Memory Standards
- How Translation Memory Integrates into Modern Localization Workflows
- Choosing Translation Memory Software (and Where Awtomated Fits)
- Future of Translation Memory
- Key Takeaways
- Conclusion