Machine Translation Post-Editing (MTPE): A Complete Guide for LSPs
Key Takeaways
- Machine translation post editing (MTPE) combines neural MT engines (e.g., Google, DeepL, Microsoft) with professional linguists to deliver faster, cheaper translations without sacrificing essential quality.
- There are two primary MTPE levels—light and full—and most business workflows in 2024–2025 mix them based on text type, risk, and budget.
- MTPE works best for high-volume, repetitive content (manuals, FAQs, product catalogs) and is often a poor fit for highly creative or very sensitive texts (brand campaigns, poetry, some legal documents).
- Standards like ISO 18587:2017 and clear project guidelines (style guides, term bases, quality thresholds) are critical to getting consistent value from MTPE.
- Companies should treat MTPE as a strategic process—measure edit distance, speed, and quality regularly—and refine engines, workflows, and training over time.
What Is MTPE?
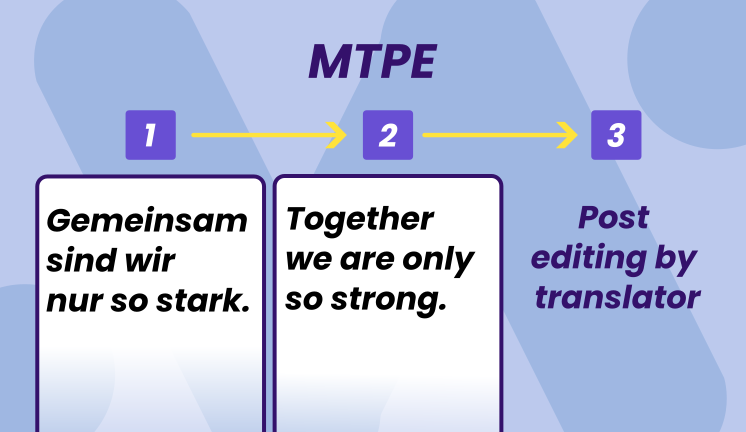
Translation post editing MTPE is a translation workflow where a machine translation engine produces a first draft, and a human post-editor improves it for accuracy, fluency, and brand fit. Instead of starting from a blank page, post editors work with machine translated text as their foundation.
Modern MTPE is usually based on neural machine translation (NMT), which became widely adopted around 2016. By 2023–2025, most enterprise translation management systems embed multiple machine translation engines—Google Neural Machine Translation, DeepL, Microsoft Translator, and others—allowing automatic selection based on domain and language pair performance.
The key shift in post editing machine translation is cognitive: linguists move from creating translations to refining them, which changes both speed and mental load.
This workflow contrasts sharply with traditional human translation, where a professional translator works directly from source to target language without any machine generated draft. MTPE can target different quality levels, from “good enough to understand” for internal documents to “indistinguishable from expert human translation” for customer-facing content.
MTPE is now standard practice in localization for software, e-commerce, SaaS, and support content worldwide. Organizations use it to handle high volumes of content that would be impractical—or prohibitively expensive—to translate from scratch.

Light vs. Full Post-Editing
The localization industry recognizes two primary MTPE levels: light post editing and full post editing. Real-world projects often sit on a spectrum between them, and as NMT improves, some providers use more granular quality tiers instead of a strict binary split.
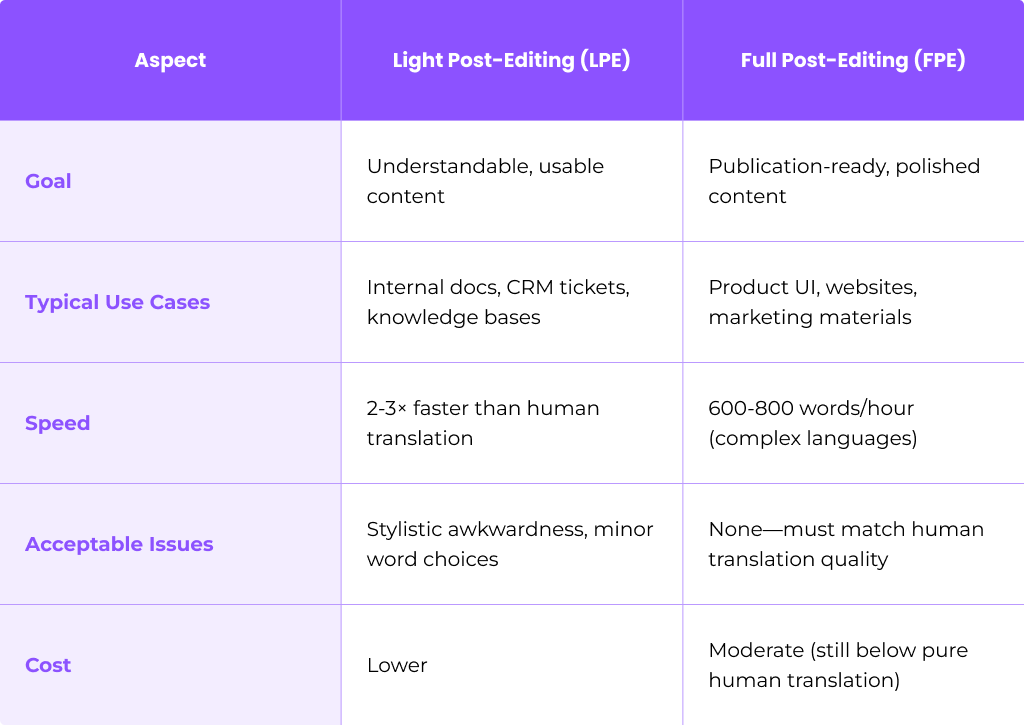
Light post editing focuses on intelligibility and essential correctness—making sure the machine translation output is understandable and free of critical errors. Full post editing aims at publication-ready text that meets a detailed style and terminology brief.
Agreeing on the level at project kickoff is essential. Teams should establish specific examples of “allowed” versus “not allowed” edits to prevent confusion and ensure consistent output across linguists.
Light Post-Editing (LPE)
Light post editing represents minimal editing intervention. The goal is fixing mistranslations, terminology errors, and grammar mistakes that block understanding or change meaning—nothing more.
Typical use cases for LPE:
- Internal documentation
- CRM tickets and support logs
- Large knowledge bases
- User-generated reviews
- Social media monitoring
- Low-risk data feeds
Expected productivity gains are significant: often 2–3× faster than traditional human translation when mt output is decent and language pairs are well supported.
What to fix in LPE:
- Mistranslations that change meaning
- Terminology that violates approved glossaries
- Grammatical errors that impede comprehension
- Missing or added content that alters intent
What to ignore in LPE:
- Stylistic awkwardness that doesn’t affect meaning
- Minor word-choice preferences
- Non-critical punctuation
- Phrasing that sounds slightly “machine-like” but remains clear
The key discipline in LPE is restraint. Over editing defeats the purpose—if linguists rework every sentence for style, the speed advantage disappears.
Full Post-Editing (FPE)
Full post editing is thorough revision that brings raw machine translation output up to a level comparable to expert human translation in the same domain. This is the approach required when quality standards are non-negotiable.
Post editors address:
- Accuracy and completeness
- Fluency and natural expression
- Tone of voice and register (formal vs. informal pronouns such as “Sie” vs. “du” in German)
- Formatting and layout
- Brand terminology and style guide compliance
Typical use cases for FPE:
- Product UI strings and software interfaces
- Customer-facing websites
- Marketing materials (with caveats for highly creative content)
- Regulated content (medical device IFUs, financial reports)
- High-visibility legal texts
Realistic throughput ranges from 600–800 words per hour for complex languages like Japanese or Arabic, compared to 200–400 words per hour for from-scratch human translation. European language pairs often achieve higher FPE rates.
Example scenario: A global SaaS company launching a multilingual dashboard in 2025 would use FPE for all UI strings. The interface must be grammatically correct, consistent in terminology, and appropriate for each target audience—there’s no room for the awkwardness that LPE tolerates.
Standards and Quality Expectations (ISO 18587:2017)
ISO 18587:2017 is the key international standard specifically for post-editing of machine translation output, published by the International Organization for Standardization in 2017. It provides a framework for organizations to implement MTPE systematically and professionally.
The standard focuses on full post editing, describing:
- Required process steps (initial review, error correction, refinement)
- Quality criteria for final output
- Competencies for professional post-editors
- Documentation and workflow requirements
How businesses can use ISO 18587 in practice:
- Include compliance requirements in RFPs when selecting translation services
- Use it as a benchmark in vendor evaluations
- Train linguists on the competencies it specifies
- Create auditable workflows for regulated industries
- Establish clear agreements between clients and language service providers
ISO 18587 does not fully codify light post editing, so LSPs and clients must define their own LPE rules and acceptance criteria.
For LPE projects, organizations need to establish bespoke guidelines tailored to content type, target audience, and risk levels. This includes documenting which types of errors must be fixed and which can be tolerated.
When (and When Not) to Use MTPE
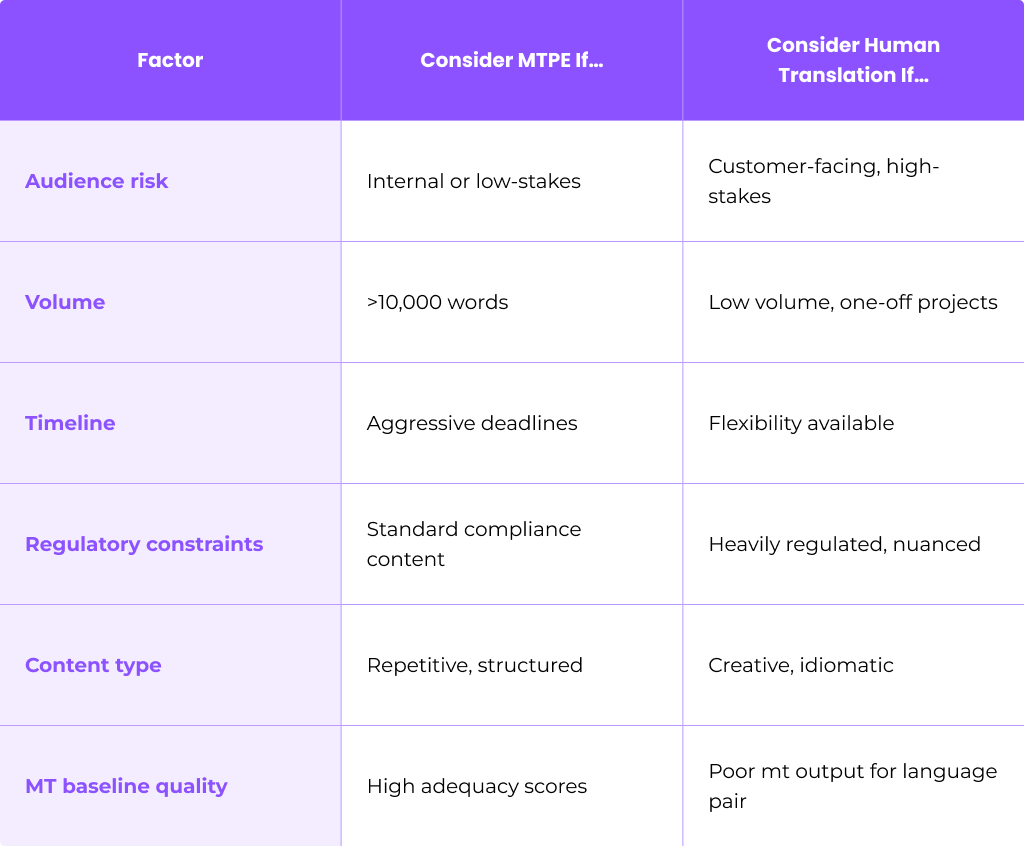
MTPE is not universally suitable. Success depends on language pair, content type, risk level, and MTquality. Making the wrong choice can result in wasted time, disappointed stakeholders, or—worse—publishing content that damages your brand.
Good candidates for MTPE:
- Repetitive technical manuals
- API documentation and technical documentation
- Standard contracts with templated language
- Support articles and FAQs
- Product descriptions and catalogs
- Knowledge base content
Poor candidates for MTPE:
- Creative content and brand campaigns
- Slogans and taglines
- Humor-driven or idiomatic texts
- Sensitive HR communications
- Nuanced legal opinions requiring human expertise
- Poetry and literary content
MTPE works best when baseline mt engine quality is at least “usable”—meaning adequacy scores above your internal threshold (many organizations target COMET scores >0.7 for initial mt output).
Decision checklist:
MTPE Workflow: From Source to Final Translation
A typical end-to-end MTPE workflow moves through several distinct phases. Understanding each step helps project managers and post editors work together efficiently.
Overview of the post editing process:
- Pre-edit and prepare source content
- Select MT engine and configure settings
- Run machine translation
- Human post editing phase
- Quality assurance checks
- Feedback loop for continuous improvement
Each phase has specific requirements and outputs. Let’s examine them in detail.
Pre-Editing and Source Preparation
Improving source text quality before translation dramatically increases mt quality and reduces post editing effort. This step is often overlooked but offers significant ROI across all target languages.
Concrete pre-editing actions:
- Rewrite long sentences (60+ words) into shorter, clearer segments
- Standardize date formats using ISO 8601
- Remove or explain culture-specific idioms
- Resolve ambiguous pronouns
- Spell-check and grammar-check source files
- Verify placeholders and tags are correct
- Apply consistent terminology throughout
Instructing writers and product teams to follow “MT-friendly” authoring guidelines—especially for documentation produced in 2024 onward—pays dividends in every language pair.
Source QA should be run before sending content to any machine translation tool. Catching errors at this stage prevents them from multiplying across all target language versions.
Selecting MT Engines and Resources
Providers often evaluate multiple machine translation systems per language pair and domain. The goal is selecting the engine that produces the highest quality mt output with minimal editing required.
Engine selection criteria:
- Supported language pairs and quality for each
- Security model (on-premise vs. cloud, data handling)
- Customization options (domain adaptation)
- Cost structure (per character, per word, subscription)
- Historical post editing effort data
Performance data from 2023–2025 typically includes BLEU scores, COMET scores, human adequacy/fluency ratings, and actual edit distance from previous projects. Modern TMS platforms can automatically route content to the best mt engine per content type and language pair.
Translation memories and terminology databases play a critical role here. When a segment has high translation memory matches (above 95%), the TM result often takes precedence over initial mt output. This ensures consistency and reduces linguist workload.
Example scenario: When comparing two engines on a technical paragraph about API integration, Engine A might produce output requiring 15% edits while Engine B requires 28%. For technical documentation, Engine A becomes the default choice for future projects of this type.
Human Post-Editing Phase
The human post editing phase is where linguists transform machine translated output into high quality translations. Post editors work segment by segment, comparing source and mt suggestions, and deciding whether to keep, modify, or retranslate from scratch.
Effective post editors understand typical NMT error patterns:
- Omitted negations (critical meaning changes)
- Gender agreement issues
- Terminology shifts from approved glossaries
- Over-literal rendering of idioms
- Hallucinated content (additions not in source)
- Decontextualized pronouns
Practical rules for the post editing step:
- In LPE: fix anything that changes meaning; tolerate minor stylistic deviations
- In FPE: address everything—accuracy, fluency, tone, and style guide compliance
- Never assume the MT is correct, even when it looks fluent
- Flag systematically bad mt segments for engine review
- Don’t retranslate everything from scratch unless MT is unusable
Modern cat tools provide keyboard shortcuts, filters, and QA plug-ins that help post editors maintain productivity and terminology consistency. Working in an integrated environment where source, machine generated translations, TM matches, and term hits appear on one screen is far more efficient than switching between applications.
Quality Assurance and Feedback Loop
Quality assurance in MTPE combines automated checks with human review. This phase catches errors that slip through the post editing task and provides data for improving future projects.
Automated QA catches:
- Spelling errors in target language
- Number mismatches (dates, currencies, measurements)
- Missing or broken placeholders and tags
- Terminology violations against approved glossaries
- Formatting inconsistencies
- Forbidden terms or phrases
Human spot checks or full reviews on samples verify that the final translation meets acceptable quality levels. This is especially important for FPE projects where the output must be indistinguishable from traditional translation.
Edit distance measures how much machine translated content differs from the post-edited version. Common metrics include Translation Edit Rate (TER) and Levenshtein distance. For well-supported language pairs like English-Spanish, edit distances typically range from 10-30% with high quality mt output.
Feeding corrected translations back into translation memories and retraining custom MT engines on post-edited corpora creates a virtuous cycle of continuous improvement.
Organizations should review metrics quarterly and adjust MTPE workflow accordingly. If edit distances consistently exceed 40-50%, it may indicate poor engine selection or unsuitable content types.
Tools That Power MTPE
A mature 2024–2025 MTPE setup integrates several tool categories into a seamless workflow. When these tools work together, linguists operate in one environment instead of juggling multiple applications.
Essential tools categories:
- Translation Management Systems (TMS)
- Computer-Assisted Translation (CAT) tools
- Machine translation engines
- Translation memory databases
- Terminology glossaries
- QA checkers
Tool selection should consider security requirements (GDPR compliance, data residency), scalability for high volumes, and support for custom MT models. Using the wrong tools—or poor integration between them—can erase much of the productivity gain expected from MTPE.
Translation Management System (TMS) and CAT Tools
The TMS serves as the orchestration layer, handling project creation, MT routing, vendor assignment, deadlines, and reporting. Project managers use it to track progress across all language pairs and content types.
CAT tools are the linguist-facing interfaces showing source segments, mt suggestions, translation memory matches, and terminology hits side by side. Modern cat tools designed for MTPE include features specifically supporting the workflow:
- Segment locking (for content that shouldn’t change)
- Fuzzy match handling with confidence indicators
- MT confidence scores
- In-context previews for UI strings
- Keyboard shortcuts optimized for editing
Typical workflow example: For a global app release in 2024, a cloud TMS ingests source files, automatically routes them to the optimal mt engine per language, and presents the combined MT output plus TM matches to post editors in the CAT interface. As editors complete segments, the TMS tracks progress, runs automated QA, and exports final translation files in the required format.
These tools reduce friction for both post editors and project managers, allowing teams to focus on quality rather than logistics.
Machine Translation Engines
There’s a fundamental difference between generic public MT engines and custom engines trained on a company’s historical translations and terminology.
Since 2018, neural machine translation has largely replaced statistical mt systems and phrase-based approaches. NMT brings significant gains in fluency—but also produces “deceptively good” errors that demand careful checking. A sentence may read perfectly naturally while containing a critical factual error or omitted negation.
Domain adaptation—training on in-domain corpora—significantly improves MTPE efficiency. Organizations in e-commerce, software localization, and finance see measurable reductions in post editing effort when using domain-adapted models rather than generic ones.
Engine selection criteria:
- Quality for specific language pairs (not all engines perform equally)
- Security model (public API vs. private deployment)
- Customization and training options
- Integration with your TMS
- Cost structure and volume commitments
Some 2024–2025 platforms automatically choose the best engine per domain and language, based on historical MTPE results. Tools like google translate may serve as a baseline, but enterprise workflows typically require more controlled environments.
Translation Memory, Glossaries, and QA Checkers
Translation memory is a database of past translations that can override mt output when a high match exists. When a source segment matches a previous translation at 95% or higher, the TM result typically takes precedence. This reduces work and ensures consistency across projects.
Glossaries (term bases) list approved product names, legal phrases, and technical terms. Both MT engines and QA tools reference glossaries to flag incorrect terminology. Maintaining accurate, up-to-date glossaries is essential for terminology consistency.
QA checkers run automated validations that catch issues humans often miss under time pressure:
- Number mismatches
- Punctuation errors
- Placeholder validation
- Capitalization rules
- Forbidden terms
Example: During QA for a 2025 financial report, an automated checker flags that “€1.2M” in the source became “€12M” in the machine translated output—a critical error that a time-pressured post editor might have missed.
Disciplined maintenance of TM, glossary, and QA rules is as important as picking a “good MT engine.”
Best Practices for Effective MTPE
Getting strong ROI from MTPE projects requires more than selecting good tools. Success is iterative: teams should pilot MTPE on selected content, measure results, refine, then scale.
The practices below form an actionable checklist for localization leads and post editors working on projects in 2024–2025.

Training and Guidelines for Post-Editors
Post-editing is not “faster translation.” It requires specific skills: pattern-spotting in raw mt output, restraint in LPE, and MT-aware research strategies.
Training topics for human translators transitioning to MTPE:
- Understanding NMT strengths and weaknesses
- Recognizing common error patterns (negations, gender, terminology)
- Using CAT tools efficiently for post-editing
- Handling fuzzy MT segments and TM conflicts
- Applying ISO 18587 principles where applicable
- Balancing speed with quality requirements
Written guidelines for each client should specify:
- Domain and subject matter
- Target audience characteristics
- Quality level (light vs. full)
- Examples of acceptable vs. unacceptable errors
- Productivity expectations (words/hour bands per content type)
Do/Don’t guidelines for post editors:
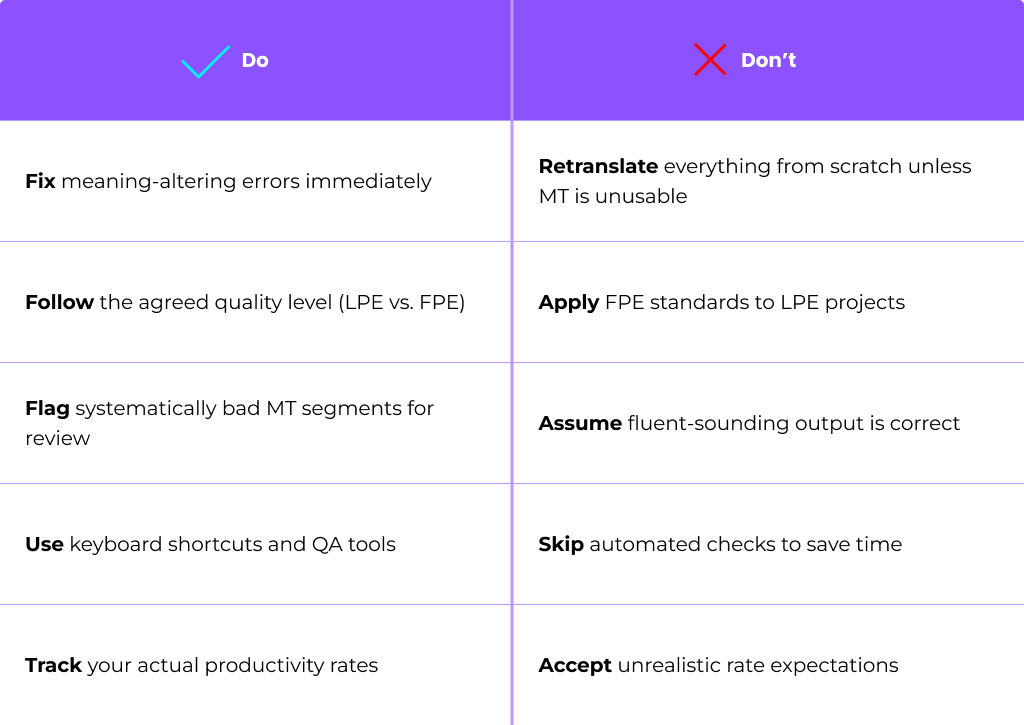
Many challenges reported by human translators—over editing, burnout, frustration with rates—stem from unclear or unrealistic MTPE instructions.
Using High-Quality, MT-Friendly Source Text
Unclear or inconsistent source content produces poor mt output, which often cancels out expected MTPE savings. Investing in source quality pays off across all target languages and future translation cycles.
Source writing rules for MT-friendly content:
- Avoid nested clauses and overly complex sentences
- Clarify pronoun references (who/what does “it” refer to?)
- Standardize terminology using approved term bases
- Remove culture-bound metaphors that don’t translate
- Use consistent formatting for dates, numbers, and units
- Keep sentences under 25-30 words when possible
Coordination between content writers, product teams, and localization should start at the planning stage. Content design workshops during 2024–2025 releases help align everyone on MT-friendly practices before content is created.
Before/after example:

The second version produces cleaner mt output and requires less post editing effort.
Measuring Success: Effort, Speed, and Quality
Measuring MTPE performance requires tracking several key metrics:
Core metrics to track:
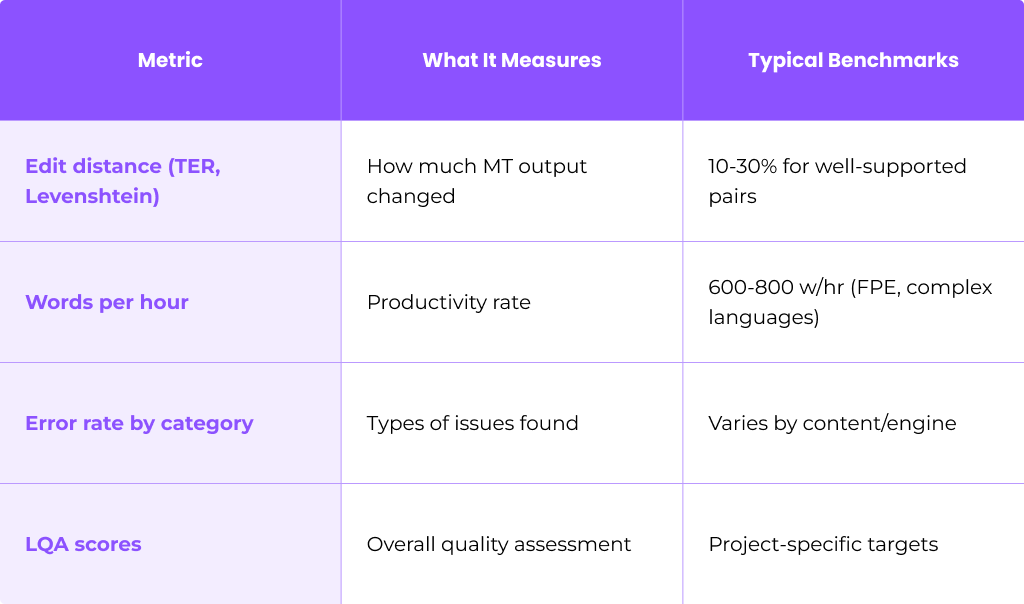
Organizations should benchmark mtpe projects against traditional translation runs. Compare cost, delivery time, and independent quality scores to determine true savings.
Very high edit distances (>40-50%) may indicate poor engine choice or unsuitable content type, prompting a return to human translation or engine retraining.
Productivity targets should be realistic per language pair. Japanese, Arabic, and Chinese typically require more post editing effort than European language pairs like Spanish or French.
Cultural and Market Adaptation
Machine translation engines often underperform on cultural nuance, politeness strategies, idioms, and region-specific variants. A translation that’s technically correct may still feel “off” to native speakers.
Post editors need cultural competence to adjust:
- Register and formality (formal vs. informal address)
- Humor and tone appropriateness
- Sensitive topics handling
- Regional variants (Brazilian vs. European Portuguese)
- Date and number formats (US vs. EU conventions)
- Local regulatory phrasing requirements
Cultural red flags that always merit human review:
- Formal/informal pronoun choices (Sie/du, vous/tu, usted/tú)
- Humor, wordplay, and idiomatic expressions
- References to holidays, customs, or cultural events
- Gender-neutral language in languages with grammatical gender
- Legal or regulatory terminology with local variations
- Marketing claims that may violate local advertising rules
Organizations expanding aggressively into new markets in 2024–2025 should treat MTPE as part of their broader localization and UX strategy, not just a cost-saving tool. Cultural adaptation often determines whether content resonates with the target audience or falls flat.
FAQ
How do MTPE rates compare to traditional human translation rates?
MTPE is usually priced below full human translation per word, though the discount varies significantly by language pair, domain, and quality level. Light post editing commands lower rates than full post editing, as the work requires less intervention. Some translation services have moved to hourly or effort-based pricing tied to actual edit distance, which more accurately reflects the work required. For well-supported language pairs with high quality mt output, MTPE rates might be 20-40% below human translation rates, while challenging pairs or content types may see smaller discounts.
Is it safe to use MTPE for confidential or regulated content?
MTPE can be safe for confidential and regulated content when proper controls are in place. Organizations should use secure, on-premise or private-cloud MT engines rather than public APIs for sensitive material. Data logging must be controlled, and appropriate NDAs plus compliance frameworks (GDPR, HIPAA where applicable) should govern all parties. Public MT APIs like consumer versions of Google Translate typically log data and may be inappropriate for confidential content. Enterprise agreements with MT providers typically include data handling terms that meet business requirements.
Will MTPE replace human translators?
MTPE changes the nature of translation work rather than eliminating it. Human translators shift focus from drafting to revising, consulting on terminology, managing quality, and handling content that MT cannot adequately process. Complex, high-stakes, and creative content still relies on expert human translation—large language models and NMT have not solved the challenges of nuance, cultural adaptation, and creative expression. The profession is evolving, with new skills becoming valuable: MT error recognition, efficient editing techniques, and the ability to add value beyond what machines provide.
How can a company test whether MTPE is worth it for their content?
Run a controlled pilot with a limited set of documents and language pairs. Select representative content types—not just the easiest material—and process them through both MTPE and pure human translation workflows. Compare cost, delivery time, and independent quality scores (have reviewers evaluate samples blind, without knowing which method produced each translation). Calculate actual edit distances to understand true mt engine quality for your content. Make decisions based on this data rather than assumptions or vendor promises. A well-designed pilot typically takes 4-8 weeks and provides clear evidence for scaling decisions.
What information should a translator receive before starting an MTPE project?
Post editors need comprehensive context to work effectively. Key items include: source samples representing the content type, target audience description, required quality level (light vs. full), details about the mt engine being used, style guides and brand voice documentation, terminology lists and glossaries, productivity expectations and rate structure, and clear instructions about which types of errors to fix versus ignore. Without this information, linguists cannot calibrate their approach correctly, leading to quality variance, over editing, or missed deadlines. Project managers should provide a written brief and answer questions before work begins.